Model Architecture
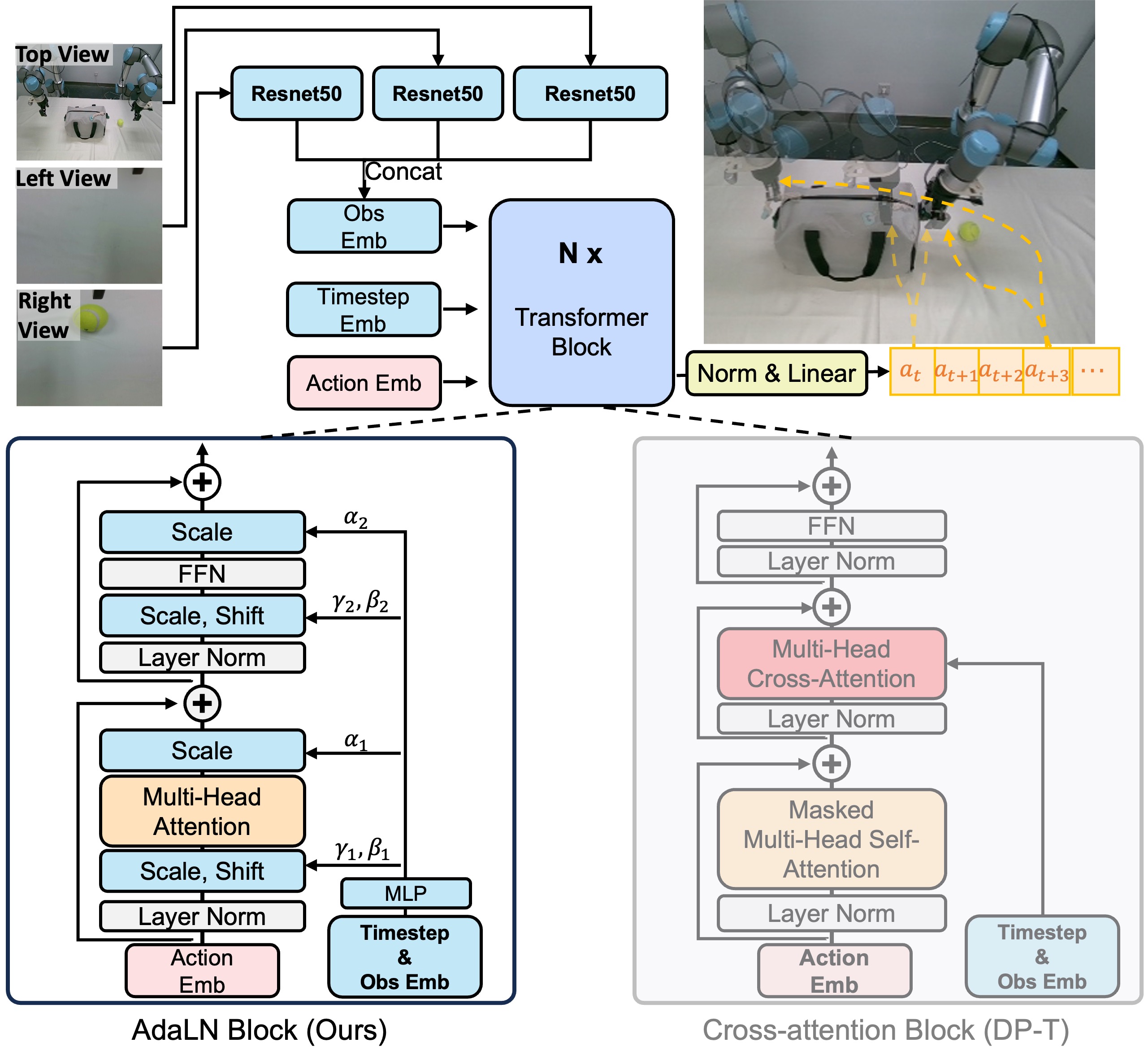
To improve the training stability of DP-T and the consistency of each action embedding, our proposed ScaleDP model makes two key modifications to the original DP-T model. (1) Compared to fusing conditional information with cross-attention in DP-T, ScaleDP fuses the conditional information with adaptive normalization layers, which can stabilize the training process of the model. (2) ScaleDP uses an unmasking strategy that allows the policy network to "see" future actions during prediction, helping to reduce compounding errors.
Experiments
We investigate whether ScaleDP can get better performance across a wide spectrum of robot manipulation tasks and environments. To this end, we evaluate the performance of ScaleDP on 7 real-world robot manipulation tasks, including 4 single arm tasks and 3 bimanual tasks.
Quantitative Comparison
| Model | Single Arm Tasks | Bimanual Tasks | Average | |||||
|---|---|---|---|---|---|---|---|---|
| Close Laptop | Flip Mug | Stack Cube | Place Tennis | Put Tennis into Bag | Sweep Trash | Bimanual Stack Cube | ||
| DP-T | 80 | 70 | 50 | 5 | 20 | 50 | 0 | 39.28±29.08 |
| ScaleDP-S | 85 | 70 | 50 | 30 | 100 | 50 | 10 | 56.42±28.87 |
| ScaleDP-B | 80 | 65 | 50 | 55 | 100 | 60 | 10 | 60.00±25.77 |
| ScaleDP-L | 95 | 80 | 70 | 50 | 100 | 80 | 90 | 80.71±15.68 |
| ScaleDP-H | 95 | 95 | 90 | 70 | 100 | 95 | 100 | 92.14±9.58 |
Qualitative Comparison
Qualitatively, we observe that ScaleDP works more smoothly and precisely compared to DP-T.
ScaleDP (Ours)
DP-T
BibTeX
@article{zhu2024scaling,
title={Scaling diffusion policy in transformer to 1 billion parameters for robotic manipulation},
author={Zhu, Minjie and Zhu, Yichen and Li, Jinming and Wen, Junjie and Xu, Zhiyuan and Liu, Ning and Cheng, Ran and Shen, Chaomin and Peng, Yaxin and Feng, Feifei and others},
journal={arXiv preprint arXiv:2409.14411},
year={2024}
}